Frequency Analysis
The widespread use of computers and the growing availability of texts in electronic form allow teachers and researchers to easily analyse texts. By calculating the most frequently occuring words and teaching/learning those, students are able to understand a language at an accelerated pace.
Other uses for this capability includes searching joblists for the most popular skill to aquire; looking for the the most commonly asked questions in a digest of email etc.
Analysis of the Torah in Hebrew
(The Torah is the first five books of the Bible)
Plot of fraction of words recognised (vertical axis) versus number of most frequent words known in the Torah -
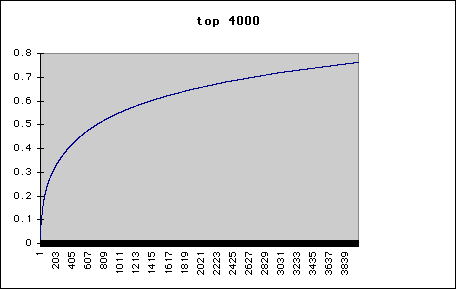
To read the graph, consider the following example -
Say you know a vocabulary of the two hundred most frequent words. Go to the horizontal axis and identify where this couresponds to on the vertical axis. 200 words corresponds to mastery of .3 or 30% of the text, guaranteed.
To summarise, if you know -
| Hebrew Vocabulary | |
|---|---|
| Words | % |
| 200 | 30 |
| 500 | 45 |
| 1000 | 55 |
| 2750 | 70 |
Another way of looking at this is:
56% of the text is known using a vocabulary of 1075 words, that is all
words occuring 10 or more times -
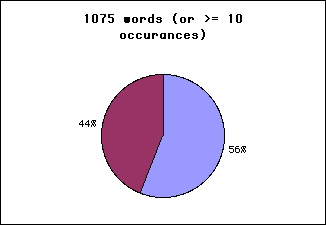
Looking at the list shows the large tail of words (44%) are made up mostly of prefix/suffix versions of the known words, that is the... and... from... etc, and so the perhaps 50% of those words will be known. A proper analysis is more involved than a simple wordcount alone and it seems required.
The Online Bible includes a BHM version, which places a colon (:) between the prefixes and the root words. Breaking the words on this colon, and at a hyphen then running the wordcount again gives the following more heartening results. (Remember also that if the suffixes are removed as well the wordlist shrinks again).
Plot of fraction of words recognised (vertical axis) versus number of most frequent words known in the Torah (prefix modified version) -
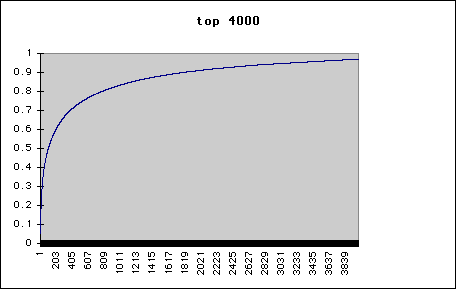
84% of the Torah (prefix modified version) is known using a vocabulary of 1061 words, that is all words occuring 10 or more times -
| Torah Hebrew Vocabulary (prefix modified version) | |
|---|---|
| Words | % |
| 200 | 60 |
| 500 | 75 |
| 1000 | 85 |
| 2750 | 95 |
Plot of fraction of words recognised (vertical axis) versus number of most
frequent words known in the Tanach (entire Hebrew Bible, prefix modified
version) -
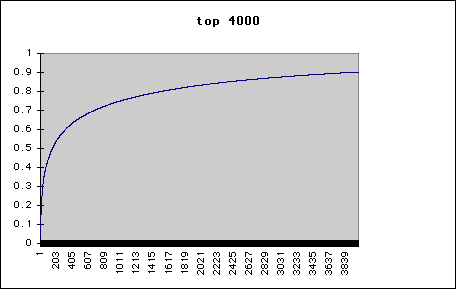
| Tanach Hebrew Vocabulary (prefix modified version) | |
|---|---|
| Words | % |
| 200 | 55 |
| 500 | 65 |
| 1000 | 75 |
| 2750 | 88 |
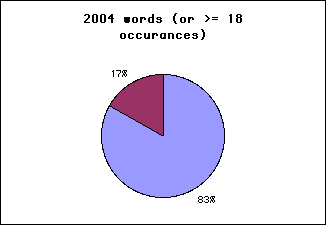
83% of the Tanach (entire Hebrew Bible, prefix modified version) is known using a vocabulary of 2004 words, that is all words occuring 18 or more times -
Lets now compare this to the same text translated into English.
Analysis of the Torah in English
(Text taken from the Online Bible, Revised Standard Edition)
Plot of fraction of words recognised (vertical axis) versus number of most frequent words known in the English Torah -
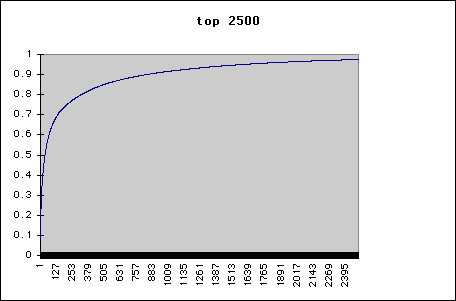
This is somewhat of a surprise, as one would expect English to have many more words than the Hebrew. English has its origins in three languages - Latin (the classic languague shared my modern European languages), French (from the Normandy conquests) and Anglo-Saxon. For example the three words sovereign, monarch and king show this heritage that gives English novelists "just the right word". The Revised Standard Edition is not a simplified English translation.
However, this is explained by the English word always appearing the same. Students of English, take heart!
Download software and materials used for this analysis